Building a Predictor for Credit Default Risk Evaluation
Machine Learning
Random Forest
XGBoost
Financial Data
Risk Modeling
Incremental Learning
Table of Contents
Motivation
For a person who applies to a credit loan, there is a probability for credit default (risk). I train machine learning algorithms to build a probability model to classify if a loan application should be approved or not.
Exploratory Data Analysis
I identified some few main issues to be addressed after the initial data analysis.
- Having some features with missing values
- Imbalanced class in the target variable
Addressing Missing Values
First identified the nature (MCAR or MAR or MNAR) of the missing values with the help of missingno python library.
Addressing Imbalanced classes
Compared the performances for applying SMOTE and ADASYN (Adaptive Synthetic) algorithm to balance the Target variable.
Feature Engineering
We appplied different methods to select important features so it will reduce the computational time, the risk of overfitting and
complexity of interpretation.
- Recursive Feature Elimination (RFE)
- \( \chi^2 \)
- Univariate Feature Selection : ANOVA F-value
- Information Value (IV) and Weight of evidence (WoE)
- Correlation
- Threshold
- Bortua Algorithm
Hyperparamter Tunning
Applied Optuna that utillizes Bayesian optimization algorithm for sampling hyperparamtes
Results
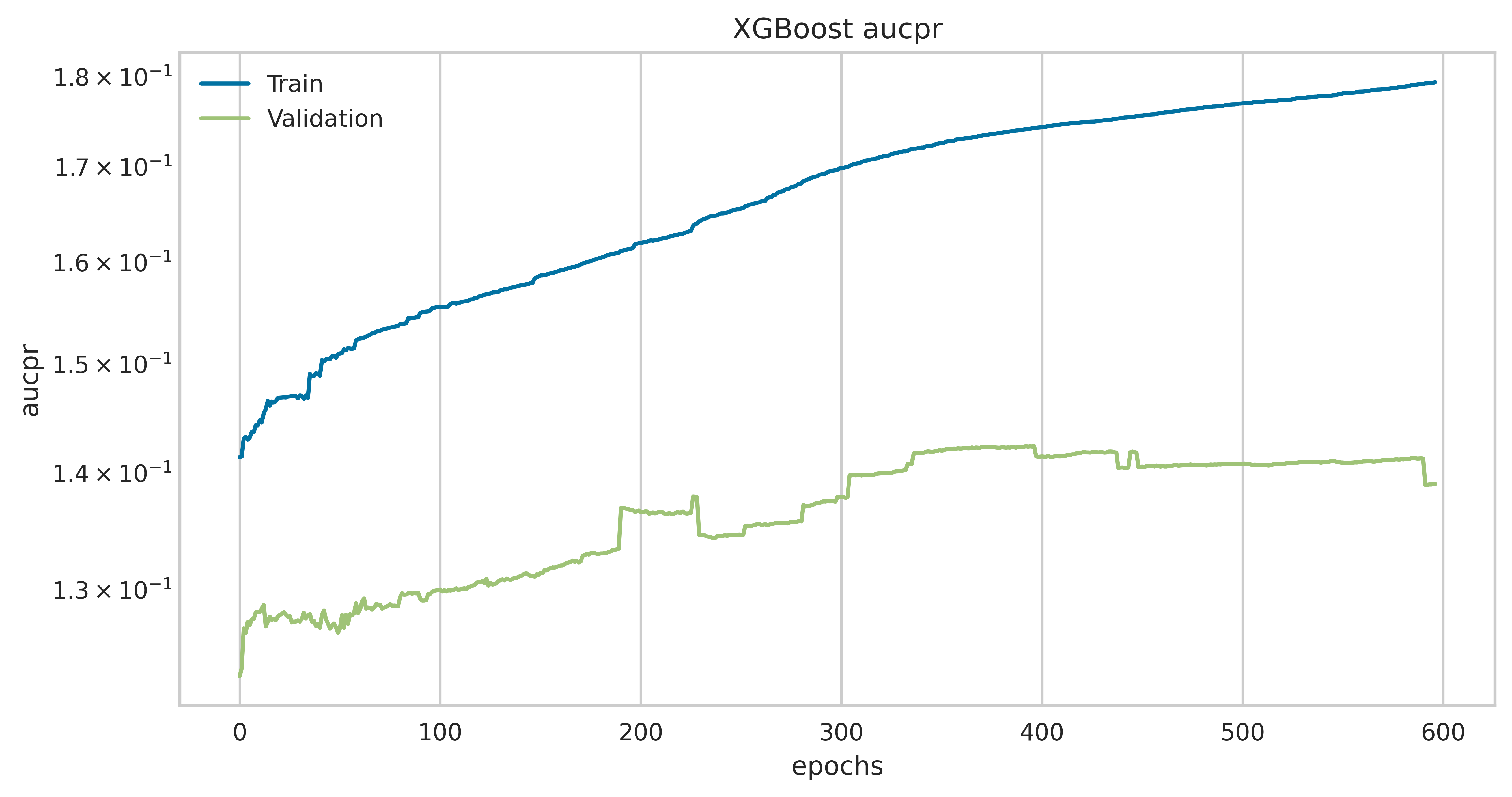 Evolution of Precision-Recall AUC score during the training of a XGBoost model.
Evolution of Precision-Recall AUC score during the training of a XGBoost model.
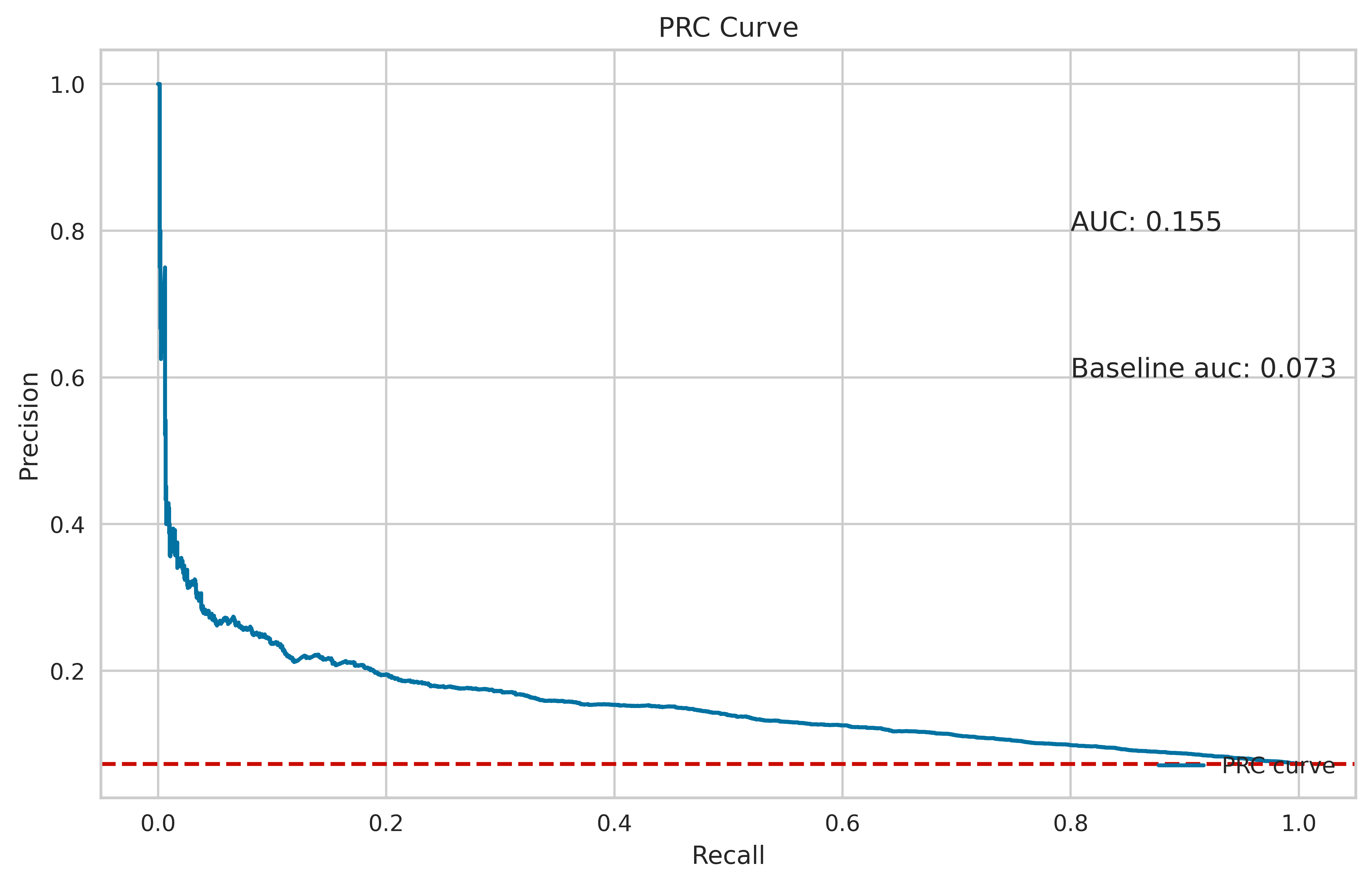 Precision-Recall Curve for the best XGBoost model.
Precision-Recall Curve for the best XGBoost model.
Impact
The model has a 0.66 ROC-auc score.